Speculative Fiction Bot
This is the source code for a bot being run on the Reddit account u/SFF_Robot.
The program continually scans comments across the entire site for mentions of science fiction and fantasy book titles. It uses a dataset of book title/author pairs that were scraped from the Speculative Fiction Database, a compendium of all known science fiction/fantasy literary works.
If an SF/F book title is detected, the bot checks if the author’s name is also present in the comment in order to reduce false positives. If both these conditions are met, the bot searches YouTube for an audiobook of the mentioned title, then replies with a link to it should one be found.
Link to full repo after the code.
import praw
import clevercsv
import subprocess
import youtube_dl
import json
import pendulum
import loguru
import os
import time
import collections
import requests
import bs4
import re
class SFF_Robot:
def __init__(self):
self.bot = self.authenticate
self.catalog = self.shelf
self.responded = collections.deque(
maxlen = 100)
self.details = None
@property
def authenticate(self):
""" Log bot into Reddit. """
return praw.Reddit(
client_id = os.environ.get(
"CLIENT_ID"),
client_secret = os.environ.get(
"CLIENT_SECRET"),
username = os.environ.get(
"USERNAME"),
password = os.environ.get(
"PASSWORD"),
user_agent = os.environ.get(
"USER_AGENT"))
@property
def shelf(self):
"""
Load CSV of scraped data from Speculative Fiction Database
into program memory as a list of title/author pairs.
"""
with open(
"isfdb_catalog.csv",
"r", encoding = "UTF-8") as isfdb_catalog:
isfdb_catalog = clevercsv.reader(
isfdb_catalog)
return [
[row[0],row[1]]
for row in isfdb_catalog
if len(row) > 1]
def get_info(self, card):
"""
Search Youtube for title, author, and "audiobook". Retrieve details
of top result as a JSON string and load it into program memory.
"""
try:
info = subprocess.check_output(
["youtube-dl", "-i", "-j",
f"ytsearch: {card[0]} {card[1]} audiobook"])
self.details = json.loads(info)
except:
return
def core(self):
"""
Main function. Watch Reddit comment stream for title + author mentions.
Check YouTube for audiobook and reply with link if suitable one found.
"""
comments = self.bot.subreddit(
"all").stream.comments(
skip_existing = True)
for comment in comments:
text = comment.body.lower().replace(".", "")
for card in self.catalog:
if (
card[0].lower() in text
and card[1].lower() in text
and not comment.submission.id in self.responded
and not comment.subreddit.user_is_banned):
self.get_info(card)
if not self.details:
break
audio = [
"audiobook",
"audio book"]
author_format = [
name.lower() for name in card[1].split(" ")
if len(name) >= 3]
if (
self.details["duration"] > 10800
and card[0].lower() in self.details[
"title"].lower()
and any(
item in self.details[
"title"].lower() for item in audio)
and all(
item in self.details[
"title"].lower() for item in author_format)):
saw_the_sign = (
"""[^(Source Code)](https://capybasilisk.com/posts/"""
"""2020/04/speculative-fiction-bot/) """
"""^| [^(Feedback)](https://www.reddit.com/message/"""
"""compose?to=Capybasilisk&subject=Robot) """
"""^| [^(Programmer)](https://www.reddit.com/u/"""
"""capybasilisk) """
"""^| ^(Downvote To Remove) """
"""^| ^(Version 1.4.0) """
"""^| ^(Support Robot Rights!)""")
comment.reply(
f"""Hi. You just mentioned *{card[0]}* by """
f"""{card[1]}.\n\nI've found an audiobook of """
"""that novel on YouTube. You can listen to it here"""
f""":\n\n[YouTube | {self.details['title']}]"""
f"""({self.details['webpage_url']})\n\n*I\'m a bot that """
"""searches YouTube for science fiction and fantasy"""
f""" audiobooks.*\n***\n{saw_the_sign}""")
self.responded.append(
comment.submission.id)
with open(
"activity.csv",
"a",
encoding = "UTF-8") as actlog:
activity = clevercsv.writer(
actlog)
if actlog.tell() == 0:
activity.writerow(
["Book",
"Comment",
"Author",
"Thread",
"Subreddit",
"Time"])
activity.writerow(
[f"{card[0]} by {card[1]}",
f"{comment.body}",
f"{comment.author}",
f"{comment.submission.title}",
f"{comment.subreddit}",
f"{pendulum.now().to_datetime_string()}"])
self.details = None
break
break
if pendulum.now().to_time_string().endswith(
"0:00"):
self.tidy()
def tidy(self):
""" Remove downvoted comments to comply with Rediquette. """
replies = self.bot.user.me().comments.new(
limit=100)
for reply in replies:
if reply.score < 0:
with open("deleted.csv", "a", encoding = "UTF-8") as removed:
deleted = clevercsv.writer(removed)
if removed.tell() == 0:
deleted.writerow(
["Comment",
"Parent",
"Thread",
"Subreddit",
"Time",
"Score"])
deleted.writerow(
[f"{reply.body}",
f"{reply.parent().body}",
f"{reply.submission.title}",
f"{reply.subreddit}",
f"{pendulum.from_timestamp(reply.created_utc)}",
f"{reply.score}"])
reply.delete()
def eventlogger(self, event):
"""
Write unexpected error messages to file before program is restarted.
"""
eventlogger = loguru.logger
eventlogger.add(
sink = "events.log",
level = "WARNING",
format = "\n\n\n\n{level} {time: {time:DD-MM-YYYY HH:mm:ss}}\n"
"Elapsed Time: {elapsed}\n"
"File: {file}\n"
"Message: {message}")
eventlogger.exception(event)
@staticmethod
def librarian():
"""
Scrapes metadata of science fiction and fantasy literary works
from The Internet Speculative Fiction Database and stores them in
a CSV file. If site structure changes significantly, code may stop
functioning properly.
"""
card = 0
for entry in range(200000):
try:
card += 1
page = requests.get(
f"http://www.isfdb.org/cgi-bin/title.cgi?{card}")
parsed = bs4.BeautifulSoup(
page.content,
"html.parser")
content = parsed.find(
id = "content").text.split("\n")
content_string = "##".join(content)
content_title = re.search(
"Title:\\s+[^#]+", content_string).group(0)
title = content_title.split(": ")[1]
content_author = re.search(
"Author:##[^#]+", content_string).group(0)
author = content_author.split("##")[1]
content_date = re.search(
"Date:\\s+\\d+\\-\\d+\\-\\d+", content_string).group(0)
pubdate = content_date.split(" ")[1]
content_type = re.search(
"Type:\\s+[^#]+", content_string).group(0)
booktype = content_type.split(": ")[1]
accepted_booktype = [
"NOVEL",
"SHORTFICTION",
"COLLECTION",
"ANTHOLOGY",
"OMNIBUS",
"POEM",
"NONFICTION",
"ESSAY"]
with open(
"SFF_Dataset.csv", "a", encoding="UTF-8") as sff:
dataset = clevercsv.writer(sff)
if sff.tell() == 0:
dataset.writerow(
["Title",
"Author",
"Publication Date",
"Type"])
if booktype in accepted_booktype:
dataset.writerow(
[title,
author,
pubdate,
booktype])
except:
print(
f"Skipping entry no. {card}: Empty article.", "\n" *4)
continue
if __name__ == "__main__":
while True:
try:
run_robot = SFF_Robot()
run_robot.core()
except Exception as event:
run_robot.eventlogger(event)
time.sleep(600)
continue
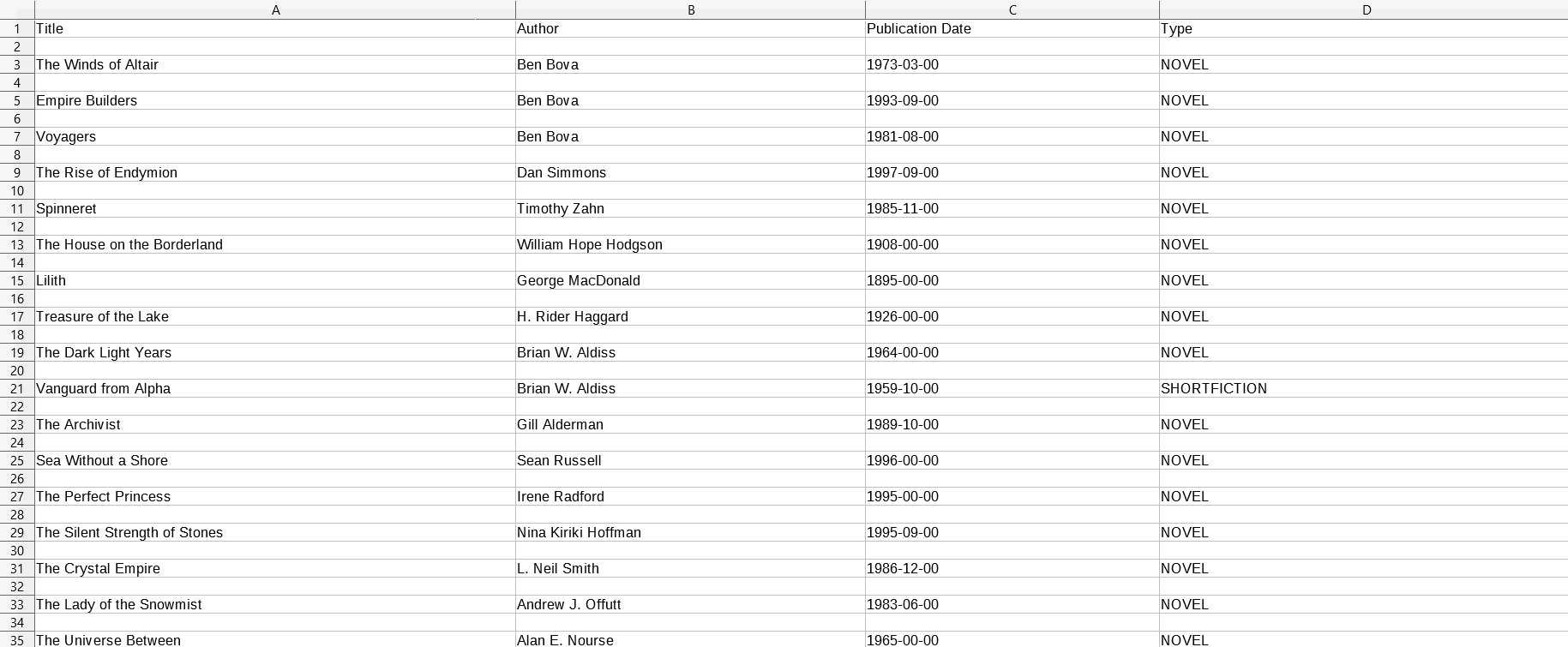
Below is how the final dataset (which is generated by the “librarian” static method) looks in Calc from LibreOffice:
The bot is run continuously on a remote Linux server, which I also use to host this website.
Full code repo available on Github
I’ve also put the dataset up on Kaggle
Related posts:
EXP-RTL: Exponential Retaliation In Iterated Prisoner’s Dilemma Games
Interleaved Neighborhood Algorithm: Fully Exploratory Optimization
Cryprotrading With A Randomized Buying Strategy
2020-04-02 06:30 +0000